
A Multi–queue Scheduler For Plan 9
17 May 2014I’m excited to be working on improving the Plan 9 scheduler under the Google Summer of Code program! Instead of vanilla Plan 9, I’ll be working on a fork of Plan 9 called 9atom. Project code will be publicly available on Bitbucket: mqs-nix
Since the application period is over, I’ve decided to post the proposal publicly for reference. Some edits were made to improve readability.
1 Abstract
As of the 4th edition release, the process scheduler in Plan 9 makes global scheduling decisions,
utilizing a global run queue of Nrq (20+2 for real time) sub-queues,
each corresponding to a priority. This can be easily done because there is a single run queue and
single run queue lock. Hence, after obtaining the run queue lock, the scheduler can scan the list of
ready processes and make a global scheduling decision.
Load balancing is also a simple task as we can evenly distribute processes to CPUs. However, on multiprocessors (especially on large-scale SMP systems), the global run queue may become a bottleneck when the number of schedulable processes increase, as well as a point of lock contention [3]. The premise of this project would then be to mitigate this, and one way of doing that would be to have per-processor run queues. This way, we eliminate the need to serialize access to the global run queue. Scheduling decisions will then be made locally based on the run queue specific to each processor. However, to maintain reasonable system-wide balance and fairness, load balancing algorithms are must be employed to balance the load across the multiple, per-processor run-queues.
There are compelling challenges and design decisions that could potentially make this project an interesting exploration of scheduling and load balancing algorithms discussed in literature and employed in other operating systems.
2 Motivation
As mentioned previously, each processor accesses a single, global run queue for process scheduling.
Hence access to the queue must be synchronized and locked for every CPU that needs to elect a process to run.
Moreover, a processor would loop, repeatedly disabling and re-enabling interrupts, (see runproc() in 9/port/proc.c)
trying to dequeue a process if it continually fails ― busy-waiting, essentially.
A per-processor run queue would eliminate this overhead and enable processors to run the scheduling algorithm
on their local run queues. This approach also encourages processor affinity, as processes from the
local run queue tend to run (and be rescheduled) on the same CPU, better preserving hot caches.
However, load balancing is an issue that arises when loads across CPUs becomes uneven.
Designing an effective load balancing algorithm is crucial, as the benefits of a multi-queue scheduler can
quickly diminish with the extra overhead incurred by a poorly designed load balancing scheme.
3 Push/pull migration schemes for load balancing
There are numerous push and pull migration schemes operating systems use to load balance tasks among CPUs.
Both can be employed, as in the O(1) scheduler in Linux[1], but for the initial phases of this project
I will experiment with a push migration scheme, whereby the busiest CPUs will foist tasks onto less loaded
CPUs determined when load_balance() is called. This scheme was chosen over pull migration because it reduces
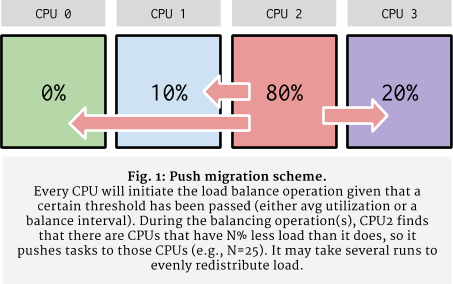
run queue contention, especially if load across processors is heavily imbalanced. For example, in
Figure 1 below, a pull migration scheme would have CPU{0,1,3} contend for CPU2’s run queue in an attempt to
pull tasks to their respective run queues. In the reverse situation, CPU2, finding that CPU{0,1,3} are
less loaded than it (an example criterion could be to initiate push migration when a CPU’s load is 25% less
than its current load), will select tasks from its own run queue to push to other CPUs.
Load would gradually redistribute over several runs of the load balancer (once per tick, until the balance interval expires).
“Busiest” here refers to load; the definition of load will be explained later, and should be further
refined to better fit our needs as the project progresses and the strengths and weaknesses of the push migration
scheme is better understood after testing and measurements.
Each per-CPU struct will have its own local run queue from which to schedule as well as some indication of load/CPU utilization.
This indication of CPU load would be updated on every clock tick (something similar to accounttime(), see 9/port/proc.c. One could
then access m->load as a calculation of CPU utilization during that tick)
The load balancing operation could be initiated during a timer interrupt, given that the criteria have been met (either, a balance interval has passed, or the average CPU utilization of all CPUs has reached a certain threshold. This is a design decision we have to make). Here is an example of how this may be implemented:
/* trap.c */
trap() {
. . .
/* Should decide on whether or not we use a balance interval,
* or call load_balance() when the average CPU utilization
* has passed a threshold.
*/
if (clockintr) {
balancetick();
. . .
}
. . .
}During the timer interrupt we update statistics and determine whether or not a load balancing
operation should be performed. This could be done in a function invoked by the timer interrupt handler, named
balancetick() in this particular example.
/* balancetick()
* Update statistics, modify accounttime() to
* calculate per-CPU load averages instead of a system-wide statistic.
*
* Alternatively, we could come up with a different metric for load if
* the load calculated in accounttime() does not suffice for determining
* if load balancing is needed.
*/
balancetick() {
/* update load statistics.
* could invoke accounttime(), but that may have already
* been called prior.
*/
/* if we decide to use the interval approach */
if (balance interval has passed) {
load_balance(); // check if we can balance tasks around
}The if-conditional will be depend on the criteria we use to determine when a
load balancing operation should be performed. The previous example above depended on a predefined
balance interval. Here’s what balancetick() might look like if we decide to load balance whenever
the average CPU utilization meets a certain threshold.
balancetick() {
/* if we decide to use the total average CPU utilization approach
if (average CPU utilization across all cores > predefined threshold) {
load_balance(); // check if we can balance tasks around
}
}The brunt of the work (including finding the most heavily loaded CPU at this point in time,
and pulling a process) would be done in load_balance()
/* proc.c */
/* Note: There are races in this pseudocode */
/* loadbalance():
* Check if we can migrate tasks to a less loaded CPU
* should there be an imbalance (push migration)
* If not, do nothing.
*
* This would be run on each processor during a timer interrupt
*/
void load_balance() {
/* find smallest load looking at each Mach machp[i] */
struct Mach *laziest = find_laziest_cpu();
/* load defined accounttime() in proc.c */
int smallest_load = laziest->load;
/* need to determine when a processor should give out work */
if (smallest load is < 25% m->load) {
lock(laziest->runq);
/* select a process to give to laziest.
* add it to laziest Mach's runq (laziest->runq[p->priority])
* which process to push? See section 4.2
*/
push_proc(m->runq);
/* do some accounting (nrdy--) + update statistics */
/* recalculate m->load, laziest->load but this is already done
* every clock tick so may not need it here
*/
/* Reminder: Must signal to the target Mach that it should re-run
* sched() upon receipt of a new process.
*/
unlock(laziest->runq);
}
/* if it doesn't pass the threshold in the first place we are done */
}During the load balancing operation we would find the “laziest” (least loaded) CPU to give tasks to. Conversely,
this we could have a pull migration procedure that finds the busiest CPU to steal from (In that case, this
routine would be named find_busiest_cpu instead).
A friend of mine noted that an O(n) search may be problematic on large SMP systems. To improve this, one could partition CPUs into processor groups, or use a O(log n) min-heap updated every few ticks with the laziest at the top of the heap.
/* If CPUs are grouped, find_laziest_cpu could potentially
* operate in a local group of CPU's instead of finding
* the absolute maximum.
* For reference, in the current Linux scheduler, a "group"
* is a single CPU in an SMP system; the definition differs
* in the case of NUMA systems
*/
/* proc.c */
struct Mach *find_laziest_cpu() {
int min = 0;
struct Mach *laziest;
for each mach in machp[] {
if (machp[i]->load < min) {
min = machp[i]->load;
busiest = machp[i];
}
}
return laziest;
}To reap the benefits of a multi-queue scheduling scheme we must account for scheduling latencies and cache
invalidations due to process migration. If the load balancing operation is run too aggressively,
the costs may outweigh the performance benefits. Thus we must decide when and how often the load balancing operation
should run as to mitigate these costs as much as possible. Thus this brings us to the next issue to address
― when and how often should load_balance() be invoked?
4 Mitigating the costs of process migration
4.1 When to load_balance()?
As for when the load balancing routine is invoked, there are two approaches I have been thinking about:
-
Invoke
load_balance()every balance_interval. We don’t want to invoke the routine on every clock tick, as that would incur inordinate amounts of overhead from constantly checking for load imbalance across all cores, latency costs from run queue locking and process migration, etc. The Linux O(1) scheduler follows an approach similar to this balance interval scheme [1]. I am currently leaning towards this first option, as it will be easier to start out with. -
Invoke
load_balance()after some threshold of average CPU utilization across all CPUs has been passed [2]. Thus the load balancer would only run when deemed necessary. For example if the loads of a 4-core system are as follows CPU1 = 50%, CPU2 = 85%, CPU3 = 25%, CPU4 = 55%, Avg CPU usage = 53.75%, and the threshold is 50%, the load balancer would run. If the threshold were 85%, it would not run. One downside of this approach is that average CPU utilization across all cores would be computed on everybalance_tick(). In addition, a termination condition has to be determined (what if all CPU’s are running at 80%? Then we should be looking at imbalance, not necessary average utilization).
4.2 Picking processes to migrate
When we migrate a process from a busy CPU, which process should be selected? For now I’ve determined that the following could be used as a criteria for selecting a process to pull:
-
A non-running, high priority process, as it is important to distribute high priority processes.
-
Has a low
p->cpu(decayed average cpu time for this process), as it is less likely to be cache hot (compared to processes that have spent more time in the CPU).
EDIT: I recently discovered this is CPU-agnostic, I could add a new per-process field that keeps track of
average CPU time for a process on its current processor (p->machno).
This will be reset when a process migrates.
- Ignore wired and real time processes they should stay on their CPU.
5 Determining CPU utilization
How should we determine load on a CPU?
The per-processor Mach struct already contains a field that represents load,
calculated by accounttime() on every timer tick; however, this load field is only
calculated and set on the boot processor as a global load statistic. It is a decayed load average
that takes into account the number of ready processes on the (global) run queue and
the number of actively Running processes across all CPUs. It approximates the load over the last second,
“with a tail lasting about 5 seconds” (proc.c). This will have to be modified to calculate the load
statistic per core, not a global system load average. Each CPU would then have its own m->load field,
not just the boot processor (CPU0MACH) as it is currently.
6 Testing
Project implementation will be based off the 9atom distribution (64-bit nix kernel).
To test the distribution of load, ideally I would perform benchmarks varying the following variables:
-
The number of cores
-
The number of spawned processes, checking how well load is distributed, while also varying the number of cores (5, 10, 50,…etc.)
-
The threshold on average CPU utilization (if we decide to go with that scheme)
-
The balance interval
-
push vs. pull migration (
find_busiest_cpuvsfind_laziest_cpu/migration thread) -
… (will think of more!)
To test latencies,
-
Establish a baseline with which we could compare, first run stress tests on a standard Plan 9 distribution with a global run queue scheduling scheme. We could do the following:
-
Vary the number of cores (5, 10, 50,…)
-
Gradually increase the number of schedulable processes (100, 1000, 10000,…) while varying the number of cores and observe whether or not latencies increase due to cores contending for the single run queue.
-
Once a baseline has been established we can run Plan9 with multi-queue scheduling implemented with the same tests as above, and determine whether or not latencies improve.
References
[1] Aas, J. Understanding the Linux 2.6 Scheduler. 2005. http://joshaas.net/linux/linux_cpu_scheduler.pdf
[2] Lim G, Min C, Eom Y. Load-Balancing for Improving User Responsiveness on Multicore Embedded Systems. 2012 Linux Symposium.
[3] Multi-Queue Scheduler (MQS) https://www.usenix.org/legacy/publications/library/proceedings/als01/full_papers/franke/franke_html/node4.html